Information here was collected and interpreted from a lecture from Stanford CS229 - video: https://www.youtube.com/watch?v=9vM4p9NN0Ts. I highly highly recommend watching it, it is a fantastic lecture.
Summary
The big picture: LLMs are basically probability distributions for sequences of words. You train them on massive amounts of internet data (pretraining), then finetune them to be helpful assistants (post-training). The key insight: bigger models + more data = better performance, almost always. Architecture details matter less than you’d think.
Pretraining: Teach the model about language by having it predict the next word in sentences. It learns patterns from the entire internet. Think of it like reading everything and learning what words tend to come after other words.
However, it’s a bit stupid in that if you give it a question like “What is the distance to the moon?”, it won’t answer but might give you the most related sentence after that which is “What is the distance to the sun?“.
Post-training: The pretrained model gives you text related to your question, not necessarily what you asked for. Post-training (SFT + RLHF) teaches it to actually answer your questions in a helpful way. SFT shows it examples of good answers, RLHF trains it to generate answers humans prefer.
For example, you want it to always answer the question “What is the distance to the moon?” with “It is 238,900 miles away.” It learns this format and when asked “What is the distance to the sun?”, it responds with “It is … distance away.” Note that if the information doesn’t exist (like if we don’t know the distance to the sun), the LLM might fill in the blank with an incorrect answer.
What actually matters: In practice, data quality(post-training ie. fine-tuning) and quantity(foundation model size ie. pre-training) matter way more than fancy architectures. Also evaluation is hard because answers are unbounded - you can’t just use standard metrics. And everyone’s bottlenecked by compute, so GPU optimization is crucial.
The bitter lesson: In the long run, only compute matters. More data + more compute, done well → model gets better. Architecture tweaks are nice but scale is what really moves the needle.
Notes:
What matters when training LLMs?
More important in academia:
- Architecture
- Training algorithm/loss
More important in industry (what matters in practice):
- Data
- Evaluation
- Systems
Pretraining vs post-training
- Pretraining is getting the model to learn about the data - for example, learning the entire internet Large language models
- Post-training Post-training of LLM is taking these models and turning them into AI assistants
Large language models
- Essentially learned probability distributions for sequences of words/tokens
- LLMs are generative - you can sample from the distribution to generate sentences
- Autoregressive (AR) language models:
- Use probability from all previous words in the sentence to predict the next word
- Essentially a for loop: generate a word, then loop back to generate the next
- Loss function: based on correctly guessing the next word in the sentence
Tokenizers
- Extremely important for LLMs
- More generalizable than just words:
- How do you match a word when there’s a typo?
- Languages with no spaces can’t be tokenized just by space
- Tokenizers use subsequences (~3-4 letters)
- Example: Byte pair encoding (BPE), one of the most common tokenizers
- Training process:
- Start with a large corpus of text
- Start with one token per character
- Merge common pairs of tokens into one token
- Training process:
- Pre-tokenization (for optimization):
- If you consider every character as a token, it takes too long
- For English: ensure tokens separated by spaces aren’t considered together
- Keep smaller tokens even with longer ones (e.g., for typos - represent typos by characters)
LLM Evaluation
- Perplexity: 2^(average loss per token)
- Limited between 1 and vocabulary length
- Intuition: number of tokens you’re hesitating between
- Not really used academically anymore (not comparable - depends on tokenizer, data, etc.)
- Still very important in development
- Academic evaluation: standard NLP benchmarks
- HELM from Stanford
- Hugging Face LLM leaderboard
- Common benchmark: MMLU (questions from many different subjects)
Data - Training on “all of the internet”
- Many difficult steps to get clean data from the internet
- Interesting concepts from the process:
- Model-based filtering: use another classifier to predict if a page is from Wikipedia, then weigh it more in training
- Domain weighting: e.g., code data helps with general logic reasoning, so upweight it
- Learning rate annealing on high quality data: overfit model to high quality data at the end
Scaling Laws - More data and larger models = better performance
- No such thing as overfitting with larger models - larger = better
- Why scaling laws matter:
- You can assume this is true and find “scaling recipes” - formulas that tell you how to change hyperparameters
- Use same hyperparameters on smaller models and extrapolate to bigger models
- Example: Don’t know if LSTM or transformer is better?
- Try both at lower scale and observe “scaling rate” (slope of scaling law)
- Things scaling laws help decide:
- Train models longer vs train bigger models
- Collect more data vs get more GPUs
- Data repetition/multiple epochs
- Data mixture weighting
- Architecture: LSTMs vs transformers?
- Size: width vs depth?
- The bitter lesson: models improve with scale and Moore’s law
- In the long run, only compute matters - architecture details don’t matter as much
- More data + more compute, done well → model naturally gets better
Training a SOTA model
- Example of current SOTA: LLaMa 3 400B
- Data: 15.6T tokens
- Parameters: 405B
- ~40 tokens/param
- Total FLOPS: 3.8 e25 FLOPs
- Compute: 16,000 H100 with avg throughput of 400 teraFLOPS
- Time: 26 million gpu hours = 70 days. From paper = ~30M gpu hours
- Carbon emitted: ~4400 ton CO2 equivalent or 2,000 round trip flights between JFK and Heathrow airport
- Next model: new models ~10x more FLOPs than previous model
Post-training of LLM
- Turns a language model into an AI assistant
- Without post-training: LLM gives text related to your input, not what you asked for
- Example input: “Explain the moon landing to a 6 year old”
- Output: “Explain the theory of gravity to a 6 year old” + “Explain the theory of relativity to a 6 year old”
- Problem: desired behavior data is what we want but scarce and expensive
- Pretraining data is not what we want but there’s a lot of it
- Solution: finetune pretrained LLM on a little bit of desired data ⇒ “post”-training
Post-training Methods
Supervised finetuning (SFT)
- Idea: finetune LLM with language modeling of desired answers
- i.e., supervised next word prediction
- Same algorithm and loss function as pretraining, just different dataset
- Different hyperparameters from pretraining → increased learning rate
- Collecting desired data: ask humans
- OpenAssistant (Kopf+, 2023) as data → this finetuning turned GPT-3 into ChatGPT
- Problem: human data is slow to collect and expensive
- Solution: use LLMs to scale data collection → have LLM generate questions and answers (e.g., 52,000 Q&A pairs for SFT)
- How much data for SFT?
- Very little needed! Only a few thousand examples
- Difference between 2k and 32k makes no difference
- Main thing it learns: format of desired answers (length, bullet points, etc.)
- Assumption: knowledge already in pretrained LLM, you’re just specializing response format
- Example: humans use bullet points for todo lists. Pretrained model has many ways to suggest a todo list, but SFT optimizes toward bullet points
- Very little needed! Only a few thousand examples
Reinforcement Learning with Human Feedback (RLHF)
Problem with SFT: behavior cloning of humans
- Bound by human abilities: humans may prefer things they can’t generate
- Hallucinations: cloning correct answers teaches LLM to hallucinate even if it didn’t know about it
- Example: if answer has a reference LLM never saw, it will make up a plausible-sounding reference
- Collecting ideal answers is expensive
RLHF
- Idea: maximize human preference rather than cloning behavior
- Pipeline:
- For each instruction: generate 2 answers from a pretty good model (SFT)
- Ask labelers to select their preferred answers
- Finetune LLM to generate more preferred answers
How do we tune the model to generate preferred answers?
Reinforcement learning using proximal policy optimization (PPO) algorithm
- What is the reward?
- Option 1: whether model is preferred to baseline?
- Issue: binary reward lacks information about why it’s preferred
- Option 2: train a reward model R using logistic regression loss to classify preferences
- Converts to continuous measure: assigns number for how much humans prefer an answer
- Option 1: whether model is preferred to baseline?
- Note: LM after PPO is no longer modeling distribution - it represents your policy from RL
- Model may give only single answer generation - not every possible thing humans might say (not a distribution)
- In theory: RL is great, and this is exactly what ChatGPT did (used PPO to generate preferred answers)
- Problem: RL is extremely messy to implement in practice
RLHF using Direct Preference Optimization (DPO)
- Essentially a simplification of PPO
- Idea: maximize probability of preferred output, minimize others
- Simpler: no additional RL model after calculating maximum likelihood
- Similar global minima, so functionally works as well as RL
- Note: DPO cannot use unlabeled data to improve its model
Challenges with RLHF: Human data
- Slow and expensive to collect
- Hard to focus on correctness rather than form (e.g., length)
- Annotator distribution shifts:
- Annotators from different backgrounds prefer different things
- Crowdsourcing ethics
RLHF using LLM Data
- Idea: replace human preferences with LLM preferences
- Price to human agreement ratio:
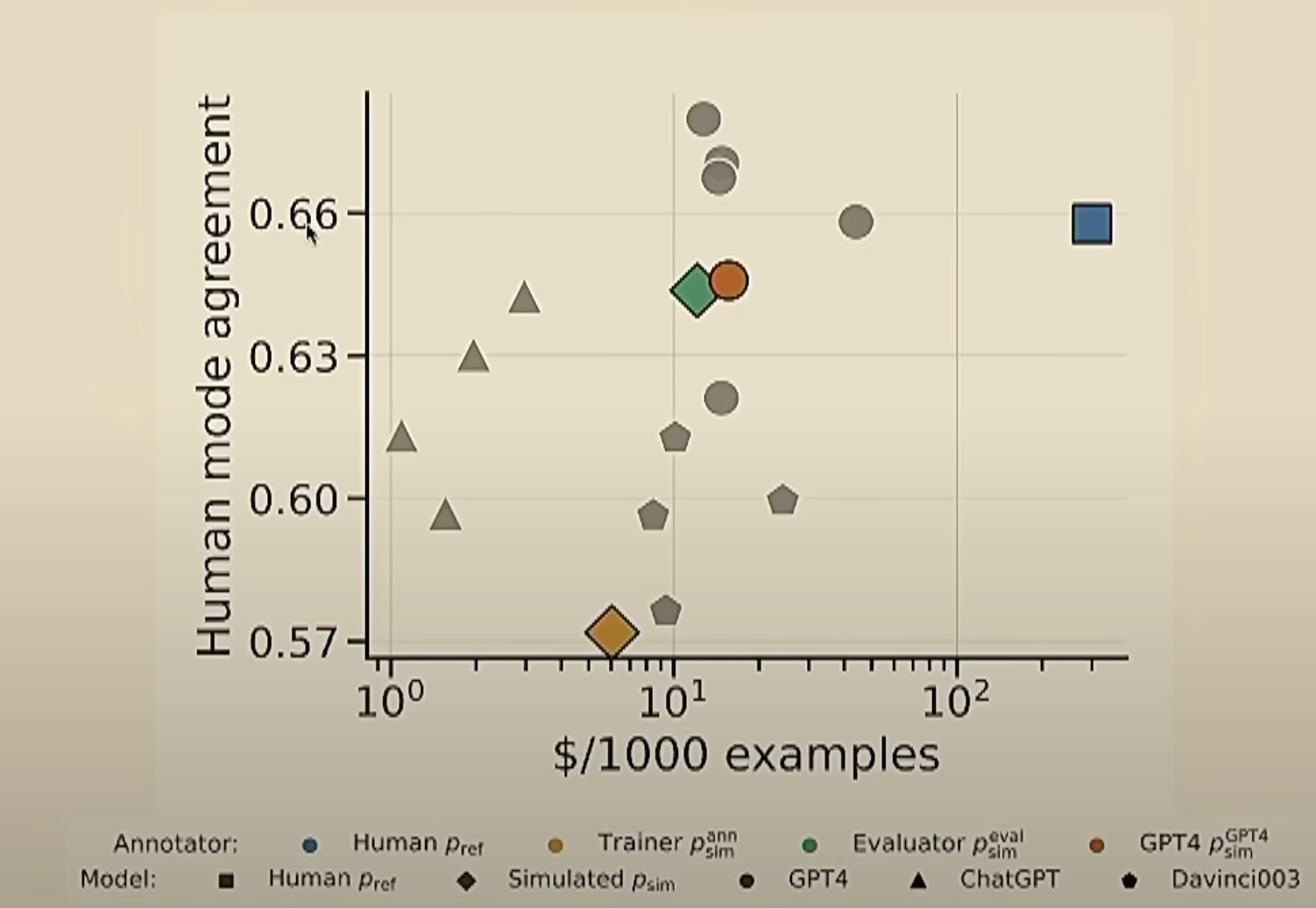
- Humans only agree with themselves 66% of the time
- LLM-generated examples: 63% agreement
- This has become standard in open source community
Evaluation of Post-training
- How do we evaluate ChatGPT? Answers are unbounded → can be any answer in the whole database
- Challenges:
- Can’t use validation loss to compare different methods
- Can’t use perplexity → not calibrated, and some aligned LLMs are policies which can have extremely low perplexity
- Large diversity of use cases:
- Generation, Open QA, Brainstorming, Chat, Summarization
- Open-ended tasks → hard to automate evaluation
- Solution: ask for annotator preference between answers
- Now evaluating different answers from different models
Human evaluation: e.g., ChatBot Arena
- Idea: users interact (blinded) with two chatbots, rate which is better
LLM Evaluation: e.g., AlpacaEval
- Idea: use LLM instead of humans
- Steps:
- For each instruction: generate output by baseline and model to evaluate
- Ask GPT-4 which answer is better
- Benefits:
- 98% correlation with ChatBot Arena
- Cheap and fast: <3 minutes and <$10 to run
- Challenge: spurious evaluation
- Example: LLMs prefer longer outputs
- Ways to control for this, but LLM bias can still propagate
LLM Systems Design: GPUs
- Problem: everyone is bottlenecked by compute
- Why not buy more GPUs?
- Expensive and scarce
- Physical limitations (communication between GPUs)
- One way to improve: massively parallelize
- Same instruction applied on all threads but with different inputs
- Optimize for throughput processing
- Fast matrix multiplication
- Compute > memory and communication
- GPUs process faster than they can be fed data
- Memory hierarchy:
- Memory closer to core → faster but less memory
- Memory further from core → slower but more memory
- Metric: model flop utilization (MFU)
- Ratio: observed throughput / theoretical throughput
- 50% is great
One way to solve: Low precision
- Lower precision floats, fewer bits → faster communication and lower memory consumption
- For deep learning: remove decimal points in matrix multiplication → 16 bits vs 32 bits
- For training: automatic mixed precision (AMP)
Another way: Operator fusion
- Problem: each PyTorch line moves variable to global memory - multiple lines = multiple movements
- Idea: communicate once - fused kernel
- Use torch.compile() - rewrites PyTorch code into one operation
Other optimizations:
- Tiling and FlashAttention
- Parallelization
- Data parallelism: copy model and optimizer to each GPU
- Model parallelism via pipeline parallelization: each GPU has a different layer